This website does not display correctly in Internet Explorer 8 and older browsers. The commenting system does not work either in these browsers. Sorry.
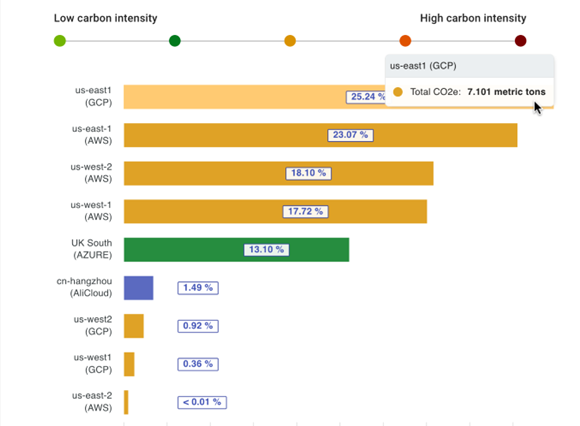
Following the recently published article on Cloud Native Sustainability: Strategies for carbon reduction the Agile meets Architecture conference team has now published the recording of my talk on the topic. In it I go over the most important concepts of green computing, I explain how organisations are estimating the carbon emissions related to their cloud usage, and I offer some insights into GreenOps and strategies to reduce carbon emssions from IT.
Over the past year I’ve spent a fair amount of time getting my head around green software and what role cloud computing plays in that space. There’s a talk that I’m currently presenting at various conferences and events. If you just want the essentials there’s now an article that I wrote with my colleague Seema: Cloud Native Sustainability: Strategies for carbon reduction.
In the article, we explore how an organisation can reduce their carbon footprint by moving to the cloud and to cloud-native architectures. And that’s an important point right there: Shifting workloads from on-premises data centres to the cloud can significantly reduce carbon emissions, but to realise the full potential of carbon reductions that a cloud-based solution can offer you will have to move to a cloud-native architecture.
Seeing all the experiments with GitHub Copilot around me I decided to take Copilot to some difficult terrain (pun intended, see below). A lot of the positive experience is reported with very common programming languages, JavaScript and Python especially, writing code related to web applications. But how would Copilot fare with a less common language and code that’s involving more complicated data structures? To find out I turned to Crellinor, my genetic programming / artificial life simulator written in Rust, which I have talked about before; and I set out to fix some todo’s in the Terrain class.
The podcast team at the Handelsblatt newspaper invited me to an episode of their So klingt Wirtschaft podcast. Jana Samsonova and I talk about green computing, responsible use of technology, and how moving to a public cloud can reduce CO2 emissions. As you may have guessed at this stage, the podcast is in German.
When I started OCMock almost 20 years ago, I would never have expected it to become so popular. Then again, at the time Objective-C was a niche language used only to develop (some) applications for the Mac. This changed with the iPhone, and dramatically so. And it changed again in about 2016 after Apple had introduced Swift and had made it very clear that Objective-C had not much of a role to play anymore. I wrote about the effect on OCMock a few years ago.
Developer experience platforms have been a hot topic for a while now, and I've talked about them with many of our clients. Last year, I distilled the essence from those client presentations into a talk that I gave a GeeCON Prague, and now the team have made the recording of the talk available on YouTube. DX platforms are not as hyped at Gen AI but if you want to make your developer teams more effective, they are certainly something to look into.
In this article, published in the funkschau magazine, I discuss an important issue that our modern software supply chains bring when it comes to security: the role of the sprawling web of dependencies.
You can read the article in the online edition of the magazine on page 42. Sorry, no direct link, and the text is in German.
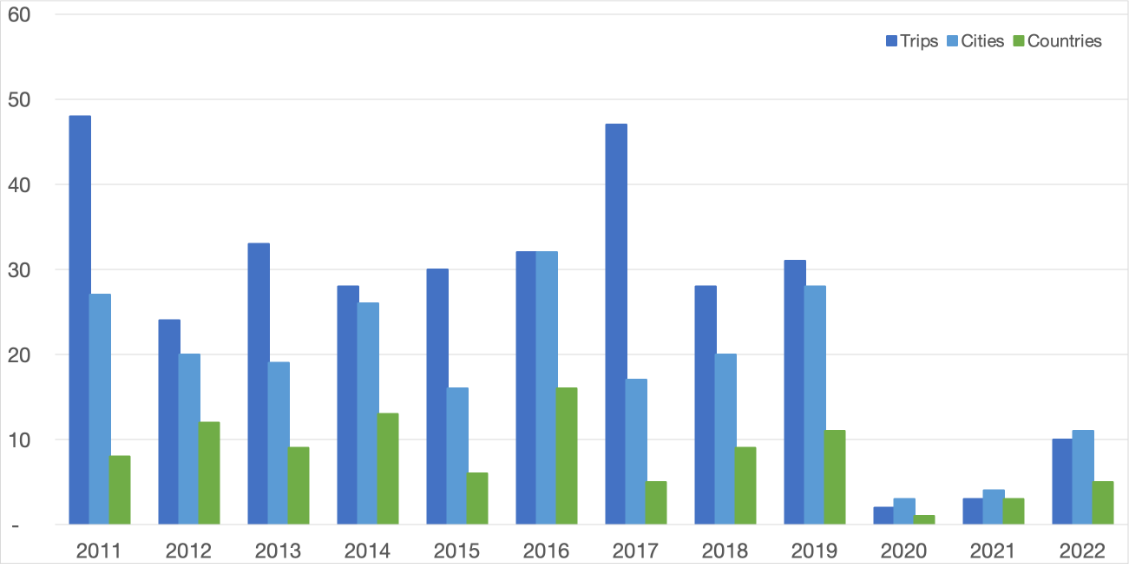
Travelling is part of being a consultant, and speaking at conferences added an extra amount of travel for me. The Covid-19 pandemic changed this quite dramatically, and looking back at 2022 I am wondering what the “new normal” could be after the pandemic.
The chart above shows some key figures related to my business travel over the past eleven years: the numbers of trips, cities, and countries I visited. A single trip can, and sometimes did, include multiple cities and countries.
The years up to 2019 differ in the details but overall the level of travel is relatively high. In 2020 this changes very visibly, and travel remains low in the “second year of corona”. Even in those years, though, there was some travel: in the first months of 2020, before the lockdowns started, and then the first trips again in autumn 2021. Barcelona in October 2021—to write a new Technology Radar—was the first trip by the way, and GOTO Copenhagen in November 2021 the first in-person conference.
In 2022, travel activity is picking up again, mostly towards the end of the year. It feels too early to make any predictions about what the new normal will look like, but I suspect it’ll remain significantly lower than in the pre-pandemic years.
As I have mentioned before, I like writing screen savers. This time I revisited one that I wrote over twenty years ago.
At the time I had decided to spend a week in a small town on the Costa Brava in Spain. Two things happened: 1) On the way out I stopped by friends in Barcelona, where I flicked through the book Maeda and Media, and 2) I had brought my Apple PowerBook with me. One of the illustrations in the book stuck with me, and I spent a few hours, while hanging out in that beach town, to code an animated version of the illustration from memory, creating the Maeda Wheels screen saver.
At first I didn’t use the screen saver because I couldn’t make it run smoothly enough. Over time, with better hardware, this got better but it still isn’t great with Intel processors driving 4K screens. So at some point, when I noticed the stuttering again, I decided to start from scratch using the low-level Metal APIs. With the book next to me I also stayed closer to the original illustration in this reinterpretation of my Meada Wheels screen saver.
Twitter’s policy changes seem increasingly erratic—like suspending accounts of journalists (see this article on The Guardian for example) or banning references to Mastodon accounts (as reported by Martin for example). Both policy changes were reverted by the way. For now. All this makes me wonder how long I want to remain on Twitter.
For now, I’ve decided to keep my Twitter account but to post on Mastodon. If you want to follow me my handle is @edoernen@toot.thoughtworks.com.
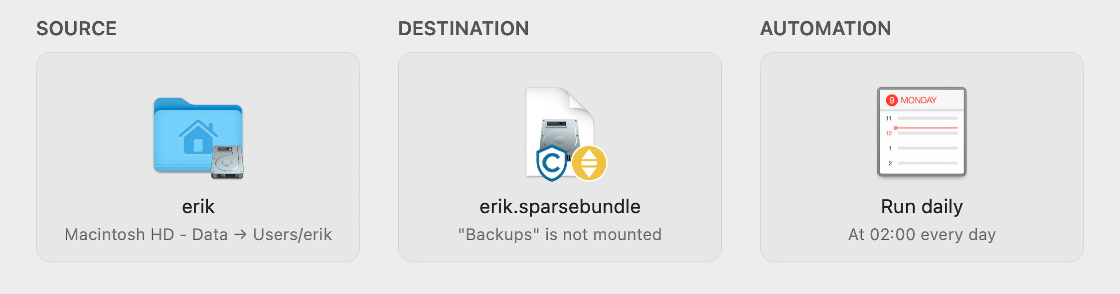
Backing up a Mac is a solved problem, right? Just attach an external drive for Time Machine and sync your files to iCloud. But what if you don’t want to have an external drive hanging off your laptop? Or if you don’t want to store all your files on iCloud? I didn’t want either, so I came up with a different strategy, which involves Carbon Copy Cloner, a NAS, rclone, and Backblaze.
A few years ago I wrote a blog post about my first impressions of Rust. This has grown into a full talk introducing Rust to experienced developers, which I have given a number of times. This is (so far) my favourite version, from GOTO Copenhagen 2021. By the way, this was my first in-person conference following the Covid outbreak.
If you've read the post or watched the video you know that the code examples are taken from one of my hobby projects, an artificial life / genetic programming simulation. Because people have asked I've now made the code available in this Github repo. Please beware, though, there is no thorough documentation on what the simulator actually does and how to make sense of the output. Since I wrote the talk the codebase has evolved a little bit, too. If you want the exact version that the talk's based on, please choose the initial version of the code in the repository.
It was fantastic to be at an in-person conference again, at GOTO Copenhagen last November. After delivering my Rust talk, Lars Jensen moderated a coversation between me and Richard Feldman of Elm fame. Based on the party keynote, in which Mark Rendle had presented his idea of the worst programming language ever, Richard and I chatted about the ideal programming langauge. The video has now been released.
For a long time Eberhard Wolff has been hosting the Software Architektur series. In episode 104 Eberhard and I talk about DevSecOps, one of my favourite topics at the moment. Please note the conversation is in German.
Somehow I have a weak spot for screen savers, for writing screen savers that is. The combination of programming, maths, and beauty is just very appealing to me. So, when Thoughtworks went through the brand refresh last summer I took that as an invitation to write a new company screen saver. (I had written the previous ones, too.) The new screen saver animates one of the illustrations that were created as part of the brand refresh.
It is written in Swift but this time I didn't go for the low-level Metal graphics APIs. Instead, I used a higher-level abstraction (CALayers) that make the code simple while still providing decent performance. The code is open source and available on Github here.
On websites like this one it’s still a good idea to add the option for readers to leave comments, I would argue. It opens the door for a dialogue.
Of course, I could simply add commenting functionality with one of the well-known software as a service commenting systems, but somehow I don’t want to force you, my visitors, to open accounts on some third-party system, and I’m trying to be privacy conscious with this website, which I wrote about in this post. For these reasons I chose the Juvia system many years ago. Unfortunately, at some point Juvia became unmaintained, and I found it harder and harder to run a Rails application with outdated dependencies.
Rather than trying to fix Juvia, which some other folks are doing now, I decided to write my own commenting system. (NIH is acceptable when it’s a hobby project.) Today, I’m happy to announce that a first version is in operation on this site and that the system is available as open source software.
As you might remember I have spent quite some time exploring how to apply data visualisations to codebases. My interest waned a bit with the rise of microservices, because the codebases got much smaller and the programming languages more varied (which was bad from a tooling perspective). However, when our podcast hosts Rebecca and Ashok asked me whether I was interested in joining a podcast on this topic, together with Korny, who has done some great work in this field recently, I obviously couldn't resist. Here's the result.
In one of the discussions of the Doppler group, where we create the ThoughtWorks Technology Radar, I mentioned that I saw a shift of code from the server to the browser. Mike, who is one of the hosts of our podcast series, got interested, and so did Rebecca, our CTO at ThoughtWorks. Together we recorded a conversation that retraces the twenty year history from “rich” desktop applications to systems where more than 50% of the code runs in the web browser, ending with a brief look into the future.
Since 2009 a Hackintosh has been my main computer at home. In case you are unfamilar with the concept, a Hackintosh is a generic PC built from components that runs Apple's macOS. In hindsight this was a good choice at the time but a number of factors have now driven me to buy MacBook Pro for personal use.
With the announcements by Apple at WWDC this year a beautiful symmetry seems ahead. In 2006 I bought one of the first Intel MacBook Pros and now I bought what will likely be one of the last Intel MacBook Pros. And in case you're keeping track, my PowerBook (Pismo) is still functioning, but not used anymore.
I have updated my personal Hackintosh journal with a final chapter.
A while ago I wrote a blog post about my first impressions of Rust. This has grown into a full talk introducing Rust to experienced developers, and the recording of that talk at YOW! Melbourne has just been released.
If you've read the post or watched the video you know that the code examples are taken from one of my hobby projects, an artificial life / genetic programming simulation. Because people have asked I've now made the code available in this Github repo. Please beware, though, there is no thorough documentation on what the simulator actually does and how to make sense of the output.
At the last meeting of the Doppler group, where we create the ThoughtWorks Technology Radar, my colleagues Evan, Neal, Zhamak and myself had a discussion about "serendipitous events". This is the idea of publishing events without knowing whether anyone will consume them, in the hope to create moments of serendipity, where someone discovers information in the enterprise that they can use to create new value. It's an intriguing idea that is too complex to fit the short description we can put on the radar.
The IEEE Software magazine’s September/October issue is about Software Engineering’s 50th Anniversary. I contributed an article that is loosely based on my DevOps talk. It is available without subscription here (PDF).
At work I’m seeing more and more embedded software; over the past few years in, among others, coffee machines, forklifts, and cars. Embedded software needs to be fast and extremely efficient with hardware resources. In some cases it not even acceptable to have a tiny break for some garbage collection. So, typical tech stacks for backend development can’t be used, never mind anything that uses browser technologies. Unsurprisingly, almost all embedded software is written in C++, and, in fact, that is also what I used recently for a personal project with a micro-controller.
Now, if you’ve programmed in C++ you probably didn’t find the experience all too pleasant or productive compared to the developer experience we have in modern web development (server as well as browser). I certainly feel that way, and it seems like I’m not alone. Three hugely influential IT organisations, who had to deal with writing code in C or a C-based language, each decided to invent an entirely new programming language just so that they had a an alternative. The organisations are Apple (Swift), Google (Golang), and Mozilla (Rust).
My personal experience with Swift, when I wrote the Dancing Glyphs screensaver a couple of years ago, was mixed at best. I understand that a number of design decisions in the language that annoyed me as a programmer were made to help the compiler/optimiser generate more resource efficient code, ultimately giving the users longer battery life. Looking through the remaining choices, I went past Golang, which uses garbage collection, and set my eyes on Rust.
In this post I’ll describe my first impressions, some of the frustrating moments, but also the extremely impressive performance on a larger piece of code.
Since building my current Hackintosh in 2012 I have made a number of changes to the hardware. After all, upgradability is one of the key benefits of a PC over a computer made by Apple. At this point the computer is down to just one harddrive in addition the system SSD, it is back to air-cooling for the CPU, and all components are very quiet. So, a couple of months ago I decided to get a new case, better matching the hardware in use now.
The trend in the PC industry to use more and more LED lighting hadn’t escaped me, and I feel that, in reasonable amounts, this can actually add to the look. What I had in mind was a single coloured fan on the front of the computer, but somehow I couldn’t bring myself to buy one of the many, comparatively expensive, LED-lit fans on the market, because they are, in almost every aspect, worse than the fans I have. It was then that I discovered Phanteks’ Halos Digital RGB fan frames; basically very thin frames with LEDs that are inserted between the computer case and the fan.
Now my new problem, and opportunity, was that these fan frames contain 30 individually addressable RGB LEDs, i.e. each of the LEDs can have a different colour at any moment in time. My mainboard is obviously way too old to have RGB support so I decided to use an Arduino board instead.
In June 2014, at its annual developer conference, Apple announced that they had created a new programming language, named Swift, to replace the ageing Objective-C as the preferred language for writing applications for Apple devices.
I remember this well because also in 2014 I had decided to revamp the API for OCMock, a testing framework for Objective-C that I have been maintaining for a long time. Most of the work on the framework was done in April/May, and the Swift announcement came just days before the release of the new version of OCMock.
Immediately, I wondered what impact of Apple’s announcement would have on Objective-C and, in turn, on OCMock. Given Apple’s messaging around this, it was clear that most developers would eventually move to Swift. But how many? And how quickly?
Mixing work and private life always brings its problems. That is also true for open source software, and for being a member of the communities on Github. In my case, I have a number of repositories on Github that I would classify as personal; they are not linked to my work at ThoughtWorks. Some of these are significant projects in their own right.
At the same time, an increasing number of clients I work with at ThoughtWorks keep their source code on Github. And to be specific: they use github.com itself, not the on-premise Github Enterprise version. It never felt right to use my regular Github account in such cases, and I experienced real issues because of it. For example, one client regularly ran Gitrob, my membership in their repositories was a link to my non-work repositories, which Gitrob also scanned. Due to the way it works Gitrob has a tendency to report false positives, needlessly causing concern and extra work for the client team.
So, to avoid such issues I created another Github account purely for work. Easy as that? Turns out there is a significant problem; a problem that now has simple solution, but one that is difficult to find.
In my latest talk, All Roads Lead to DevOps, I discuss how DevOps fits with modern software architecture concepts like Microservices and Cloud computing.
At a recent Technical Advisory Board meeting Sam Newman and I had a conversation about microservices and cloud computing; how they have really brought something new and helpful, but also how, as usual, they are seen as the silver bullet that will solve all our problems.
Privacy on the internet has always been important to me. I guess this is because I grew up in Germany where, in no small part due to experiences with the Nazi government and, later, the Stasi in Eastern Germany, people are generally more privacy conscious. For example, when the implications of the 180-day rule in the US Electronic Communications Privacy Act really sunk in, I moved all my personal email hosting out of the United States. Last year, I finally realised that I should talk about privacy and mass surveillance more publicly, which I then did; in a talk, in a group interview on privacy and security, and an interview about the Pixelated project.
At the same time I'm running this website. Do I put my money where my mouth is? What am I doing with this website regarding your privacy?
Our colleague Johannes Thönes interviewed Folker Bernitt and myself about the Pixelated project that Folker and I am involved with at ThoughtWorks. This interview has now been published on Soundcloud.
This year, the Java programming language is 20 years old. To mark the occasion, Michael Stal, editor of JavaSPEKTRUM, decided to publish a few anecdotes that we, the members of the content advisory board, would contribute. When I thought about what to write the hype around this year's WWDC was building up, reminding me of the following story.
It is May 2000. A few colleagues of mine and I sit in an overcrowded room at Apple's World Wide Developer Conference (WWDC), looking forward to session 407, to be presented by Rory Lydon. We're here because at our company we work with Apple's WebObjects application server, one of the very first application servers. Originally written by NeXT in Objective-C to be used with Objective-C it moved to Apple as part of the NeXT acquisition in late 1996 and was made Java compatible.
Rory is going to tell us what is going on in one part of Java land and his session has the title “WebObjects: EJB – Making the Best of a Bad Thing”. After an introduction he continues with a description of core parts of the EJB specification, and many in the audience, including myself, find hard to believe what we are hearing. Rory quotes from the specification, compares with the elegant solutions in WebObjects that have matured over years. We frown, worrying how our applications could be implemented with this EJB technology. The specification itself is the target and Rory mercilessly points out gaps and weaknesses. After further quoted passages from the specification the mood in the room brightens and, arriving at bean and container managed persistence, the first laughs can be heard. “This will never work in this form”, many seem to think.
Last month three completely unrelated, yet equally mysterious, hardware problems kept me entertained at home. Each did have an obvious explanation in the end. Getting from symptoms to diagnosis, though, required both, guesswork and luck. Sure, I'm more of a software guy but I thought that I had a decent understanding of “how stuff works”. Well, looks like things have gotten pretty complex now.
Problem #1: our trusty PS3. Symptoms: We had just bought a new TV. Excited to see how games would look like on it, I powered up the PlayStation, and was greeted with a big blank screen of nothing. The TV was definitely set to display the correct input source, but, still, there was no picture. Swapping the HDMI cable to a different port on the TV, with the PS3 running, fixed the problem. It definitely left an uneasy feeling, though.
Things got even more confusing when I tried to play again another day and was again greeted with a blank screen. Now swapping back to the HDMI port that I had originally used gave me a picture. How could that be?
My work computer is a 15" MacBook Pro. Its performance is definitely good enough for serious software development, even if the Scala compiler and the IntelliJ indexer do push it at times. In fact, performance is so good that I have been wondering how Apple and Intel have managed to get that much CPU power, and the requisite cooling, into such a small machine. That is, small when compared to desktop or workstation computers.
In contrast, my Hackintosh at home now has about 800g of metal hanging off the mainboard to cool the CPU. Granted, it is overclocked, which requires disproportionally more cooling, and it is about 50% faster than the MacBook but, still, I found it surprising just how much less cooling the MacBook seems to need.
At GOTO Aarhus 2014 Ola Bini hosted a discussion with Martin Fowler, Tim Bray, and myself covering topics such as browser security, identity providers, password managers, monopolisation of internet services, and the future of mass surveillance.
In September Michael Tiberg invited me to give my Architecture without Architects talk at the excellent FooCafe. The talk was recorded and the video is available on Youtube.
At the moment I'm playing with D3.js trying to recreate some of the polymetric diagrams pioneered in CodeCrawler. (You can see my progress on that over here.) In the process it occurred to me that it should be relatively trivial, using the same tools, to recreate the Toxicity charts we did years ago. Having an HTML5 version would be quite welcome, too, because the original implementation uses Excel features that only work on Windows.
Well, turns out it wasn't too difficult and the result is available in this Github repository. I like the fact that with HTML we can have much richer tooltips compared to the Excel version. What's even better, though, is that because it is an HTML solution I can inline the fully interactive chart in this post:
One of the aspects of our industry that I find most exciting is the amount of change and progress. Sometimes that progress means that even ideas that have come to be considered accepted wisdom need to be revisited. In some of my talks I've been arguing for a while now that we need to reconsider the general preference for buying software (over building it).
At the same time Rien Dijkstra was in the process of editing a collection of essays on the topic of sourcing IT and he kindly invited me to contribute my ideas. I was more than happy to accept his offer and I am proud to be part of this collaboration. A preview of my essay has been published on this site as an article series. Now the book is published and widely available.
Last August I completed my tenth year with ThoughtWorks, and we have a tradition to let people take a three-month long sabbatical leave after ten years. Mine got postponed a bit but now I'm off, until August.
During my leave I'll take it easy, spend more time with the family, but I'm also going to make some progress on the Softvis project that Jonathan McCracken and I started a long time ago. You can see the first steps here: softvis.github.io. More in three months. Hopefully.
If you are interested in writing up a visualisation and contributing it to the project, please get in touch! Maybe, if we get enough visualisations written up, we'll publish them in a book.
The last couple of months saw less writing and more coding. I've managed to finish a much requested feature for OCMock, namely the ability to mock class methods, which resulted in the release of OCMock 2.1.
At the same time I worked on the (long overdue) Mountain Lion version of CCMenu. It uses the notification system added in OS X 10.8 instead of Growl notifications. The new version is available via the built-in update mechanism and, as usual, from the SourceForge project site. Starting with this version, CCMenu is also available on the App Store. I'm planing to support both distribution channels for the foreseeable future.
After discussing issues with building software in part 1 and issues with buying software in parts 2 and 3, this concluding post of the series considers two approaches for organisations to deal with the buys build shift.
In part 1 of this series I discussed traditional reasons people have for buying software, which turned out mostly to be based on perceived or real issues with building software. In this post, which contains part 2 and 3, I discuss issues with buying software.
When I lived in London I used public transport a lot. Who doesn't? But for some reason, which I don't remember now, I started keeping my used travelcards in a box. I also asked Martina, my partner, for hers. As you can imagine, over the years we ended up with quite a collection. In fact, we had to buy travelcards until we moved to Clerkenwell late in 2006 because the station in Hackney, where we had lived before, didn't have Oyster card readers.
Stumbling across the box when we left London I had an idea: If there's post-it art, why not make travelcard art? I took a few years but now I've finally done it. The Travelcard Invader has arrived.
Three years ago, unhappy with Apple's hardware lineup, I decided to dip my toes into the Hackintosh world. It was a resounding success and the machine I built back then has served me well. So, last month, with Intel's Ivy Bridge and Apple's Mountain Lion out, I decided to build another Hackintosh. I have written up my experience in this article.
When a new IT solution is needed in an enterprise, maybe because the business is changing or maybe because an existing manual process should be automated, the people who are in charge of implementing the solution usually quickly get to the question: should we build the solution or should we buy a package? For a long time the accepted wisdom has been to always buy when possible and only build when no suitable packaged solution exists in the market.
In this article series, which will eventually be published in this book, I want to explore the reasons behind the existing preference for buying and, more importantly, I want to challenge the accepted wisdom and explain why I believe that the changes that have occurred in software development over the last decade have shifted the answer to the buy-or-build question away from buy and more towards build. I am not going as far as suggesting that build should be the new default but I think building software should be considered more often and it should be considered even when a suitable package exists.
Over the past few months I've spent a fair bit of time on a project using my MacBook Pro for development. This got me to run CCMenu again and, perhaps predictably, made me work on that in the evenings. While doing some long overdue refactorings I came across the need to construct domain objects in unit tests. So far I had used simple helper methods in the unit test itself, but the Java/Scala project I was on during the day made heavy use of the Builder pattern with fluent interfaces, and that got me thinking.
In the end I've come up with three variations of the Builder pattern in Objective-C, all of which have their pros and cons. In this post I want to show these patterns and invite comments on which one you prefer.
So, I've just moved back to Europe after three fantastic years in Australia. One thing I'll miss for sure is living just a few minutes away from the beach, but on the upside I'm now in easy travelling distance to a lot of great conferences. The following is a list of conferences and gatherings that I'll be at, and in some case will also speak at. Hope to see you at one!
By the way, you've probably noticed that I updated the theme of this site to reflect my new hometown, Hamburg; the picture shows part of the town hall.
Great contributions from the community keep coming to OCMock and I've now rolled them into a new release.
A major focus of this release was improved support for iPhone/iOS, and I'm happy to say that OCMock can now build as a static library for iOS and it fully supports tests on devices. There is also improved documentation on the OCMock website and an iPhone example app that shows in detail how to set up a project.
Other features of this release are support for blocks, both for call verification and argument checks, a new method to forward calls from a partial mock to the real object, which can be useful in cases where you want to verify that a method is called but still rely on the real implementation, and, last but not least, a method to reject calls on nice mocks.
More details on the OCMock page at Mulle Kybernetik.
As a consultant I often find myself in a position where I have to get to know a large existing code base quickly; I need to understand how the code is structured, how well it is written, whether there are any major issues, and if so, whether they are localised or whether they are spread throughout the code base. To get a feeling for the general quality of the code I have found Toxicity charts useful. To understand the structure, Dependency Structure Matrices come in handy. Conceptually somewhere between those two lie metrics tree maps, which I want to write about today.
A metrics tree map visualises the structure of the code by rendering the hierarchical package (namespace) structure as nested rectangles, with parent packages encompassing child packages. The actual display is taken up by the leaves in this structure, the classes. Have a look at the following tree map which shows the JRuby code base, without worrying too much about the "metrics" part yet.
At the top right I have highlighted the org.jruby.compiler package. The tree map shows that this package contains a few classes, such as ASTCompiler and ASTInspector, as well as three subpackages, namely impl, ir, and util, with util for example containing a class called HandleFactory, visible on the far right. (Visible in the full-size version.) In the following I explain how the tree maps visualise metrics, and I will explain how to create such maps from Java source code. As usual, adapting this other programming languages is relatively easy.
This is just a quick post to raise awareness for a technique that has been around for a while. In software architecture a Dependency Structure Matrix (DSM) can be used to understand dependencies between groupings of classes, that is packages in Java and namespaces in C#. There are obviously other uses, and this Wikipedia article has more background information.
Returning to classes and packages, the following matrix shows a view of some of the core classes of the Spring framework:
In this typical package DSM the packages are listed on both axes. If a package has dependencies on another package, the number of dependencies is listed at the intersection. The package that has the dependency is on the top, the package that it depends on is on the left. In the example above the matrix shows that there are seven dependencies from the beans.propertyeditors package to the core.io package.
The practice of continuous integration is gaining widespread adoption and almost every project I was involved in over the past few years used a continuous integration server to maintain an up-to-date view on the status of the build. Developers can look at the status page of the server or use tools such as CCTray and CCMenu to find out whether a recent check-in has broken the build. Some teams also use build lights, like these for example, or other information radiators to make the status of the build visible.
The reason why developers need an up-to-date build status is a common, and good, practice: new check-ins are only allowed when the build is known to be good. If it is broken chances are that someone is trying to fix it and dumping a whole new set of changes onto them would undoubtedly make that task harder. Similarly, when the server is building nobody knows for sure whether the build will succeed, and checking in changes would make fixing the build harder, should it fail.
To recap: the build must be good for a developer to be able to check in. On one of our projects this was becoming a rare occurrence, though. In fairness, the build performed fairly comprehensive checks in a complex integration environment, involving an ESB and an SSO solution. The team had already relegated some long-running tests to a different build stage, and they had split the short build, ie. the build that determines whether check ins are allowed, into five parallel builds, bringing build time down from over 45 to under ten minutes. Still, developers often found themselves waiting in a queue, maintained with post-its on a wall, for a chance to check in their changes. Not only that but everybody felt the situation was getting worse, that the build was broken more often. This was obviously a huge waste and I was keen to make it visible to management using a visualisation.
To begin with an antipodean image, using a service-oriented architecture, when it works out, can be as elegant and exhilarating as surfing on a 10 meter wave, exploiting huge uncontrollable forces to move forward at great speed. However, unfortunately, and maybe much like in the surfing world, the SOA wave often mercilessly rolls over a hapless development team, leaving them confused and wondering whether to give up on the idea or to paddle out again.
Despite its complexity a service-oriented architecture is high on almost every project's wish list. I have been involved in eight projects over the last year, sometimes directly delivering working software, sometimes reviewing or advising, and out of these eight projects six were, according to the respective architects, building a system with a service-oriented architecture. On these projects I have come across two recurring uses of language around SOA that I found noteworthy.
The main features of this release are partial mocks and method swizzling. Sometimes it's just easier to use a real object rather than setting up a complex mock from scratch, but often in such cases there is at least one method on the real object that has undesirable side effects, or a method returning a value that we would like to change for a test. With the new features in OCMock it is now possible to selectively replace individual methods on existing objects. Did I mention that I love the Objective-C runtime?
As usual the release also includes many contributions and bug-fixes from the community. More details on the OCMock page at Mulle Kybernetik.
Over the past years I have shown everyone who could not run fast enough some of the tools based on Moose. And even now I cannot resist putting a screenshot of CodeCity into this post.
Most of the Moose tools now use the MSE file format as an interchange format. By the way, if you are interested in writing your own visualisations or analysis tools it is probably worthwhile looking at MSE, reading this format is so much more convenient than parsing source code.
In Java it was always relatively easy to create MSE files. Among many other things, iPlasma can read Java source code and export to MSE. That said, iPlasma has so many interesting features itself that oftentimes no export to an external tool is necessary.
For C# the story was different and for one reason or another no tool existed that could create MSE files for C#. This has changed now. As a student project at the University of Lugano such a tool was written and, thanks to Michele Lanza, then donated for general use. I've made a few improvements and put the code into this Bitbucket repository.
At some point last year I was asked to review the architecture of the software behind a large and popular website. The resident architect explained how he had followed a modern approach, decoupling the web front-end from back-end services that provide content. To gain further flexibility he had put the front-end and the services on an ESB, mostly to cater for the possibility to make the content available to other consumers. In short, the architecture diagram looked a lot like many others: nothing to see here, move on.
The diagram above only shows one of the content services, which for the sake of this article is a service that provides contact details for a person.
Based on conversations with the project sponsors I began to suspect that at least the introduction of the ESB was a case of RDD, ie. Resume-Driven Development, development in which key choices are made with only one question in mind: how good does it look on my CV? Talking to the developers I learned that the ESB had introduced "nothing but pain." But how could something as simple as the architecture in the above diagram cause such pain to the developers? Was this really another case of architect's dream, developer's nightmare?
Admittedly, I've been struggling with the "Architect" title in the IT world. It is not that I think there's no role for architecture, far from it, but too often I've encountered architects who focus too narrowly on architecture, losing track of the realities of actual software development and the context in which the software will be used. I wonder, if there was no "Architect" title and people who are responsible for architecture would be called guide or coach or tech lead, or just the senior developer, whether things would be better.
About a year ago, in a discussion about architects, rather than trying to define what an architect is or does, we looked at what he or she should know. We expressed our ideas as mini-essays, strictly limiting ourselves to one per essay, and it turned out that, at least to my surprise, there was a lot of agreement; maybe because we hadn't come up with hard and fast rules but with ideas and guidelines.
Luckily Richard Monson-Haefel was part of that discussion and he had the resolve and means to make our thoughts more widely available. Our list of the 97 things every architect should know was collected and refined on this wiki, and is available under a creative commons license. For a more convenient read it has now also been published as a book by O'Reilly. As expected, the discussions have begun.
The JAOO conference is coming to Australia again, and I think it will be the best technical conference in Australia this year. (I admit that I'm somewhat biased as a member of the programme committee.) In the lead up to the conference we have organised what we call JAOO Nights in Brisbane, Melbourne, and Sydney. These are free events, starting at 5pm with two speakers presenting on topics that give a flavour of what the JAOO conference itself will be like.
Check out the JAOO Australia site for information on the sessions, and sign up for your city if your interested!
Update: I have reimplemented the charts in HTML5. See Toxicity reloaded.
If you are somebody who writes code you probably know that moment when you look at some code you didn't write, or some code you wrote a long time ago, and you think "that doesn't look good." Ok, more realistically, you probably think "WTF? I wouldn't want to touch that with a barge-pole!" It is not even so much about whether the code does what it should do—that takes a bit longer to figure out—or whether the code is too slow. Even if it's perfectly bug free and performs well, there's something to the way it's written. This is part of the internal quality of a software system, something that the users and development managers can't observe directly; yet, it still affects them because code with poor internal quality is hard to maintain and extend.
Now, as a developer, how do you help managers and business people understand the internal quality of code? They generally want a bit more than "it's horrible" before they prioritise cleaning up the code over implementing new features that directly deliver business value. Or even: how do you figure out for yourself how bad some code actually is in relation to some other code? These were questions that Chris Brown, Darren Hobbs, and myself were asking ourselves a couple of years ago.
The answer came in the form of a simple bar chart, arguably not the most sophisticated visualisation but a very effective one. And our colleague Ross Pettit had the perfect name for it: The Toxicity Chart. Read on to see what it is and how it's created.
One of my favourite tools to render graphs is GraphViz Dot and in an earlier entry I described how to use it to visualise Spring contexts. Today I want to showcase a different application.
Call graphs show how methods call each other, which can be useful for a variety of reasons. The example I use here is the graph rooted in a unit test suite, and in this case the graph gives an understanding of how localised the unit tests are, how much they are real unit tests or how close they are to mini-integration tests. In an ideal case the test method should call the method under test and nothing else. However, even with mock objects that's not always practical. And if, like myself, you fall into the classicist camp of unit testers, as described by Martin Fowler in Mocks aren't Stubs, you might actually not be too fussed about a few objects being involved in a single test. In either case, looking at the call graph shows you exactly which methods are covered by which unit tests.
There are several ways to generate calls graphs and I'm opting for dynamic analysis, which simply records the call graph while the code is being executed. A good theoretical reason is that dynamic analysis can handle polymorphism but a more practical reason is that it's actually really easy to do dynamic analysis; provided you use the right tools. The approach I describe in this article uses Eclipse AJDT to run the unit tests with a simple Java aspect that records the call graph and writes it out into a format that can be rendered more or less directly with Dot. Of course, this technique is not limited to creating graphs for unit test; it only depends on weaving an AspectJ aspect into a Java application.
The Spring framework has become ubiquitous in the Java world, and there are a large number of tools supporting developers of Spring-based applications. In this post I describe SpringViz; or, more accurately, my variant of it.
SpringViz helps developers with what is at the heart of a Spring-based application, the container and the contexts files that describe the beans. In larger projects these context files can grow quite a bit. Newer versions of the Spring framework introduced features that help reduce the clutter and there are vast numbers of blog posts voicing different opinions on what should and what shouldn't be in a context file but, no matter what, the number of beans in the context files will grow with the size of a project, and at some point it becomes difficult to understand the overall structure. This is no different from trying to maintain an understanding of a large codebase. In fact, I consider the context files to be code rather than configuration.
I've argued before (here and here for example) that to deal with the complexity and sheer size of software systems we need a 1000ft view. This is a view that uses visualisation techniques to aggregate large amounts of data and multiple metrics into one big picture. SpringViz provides that 1000ft view for Spring context files.
For a few releases the Apple development tools have included OCUnit and many developers have now started to write unit tests. There are lots of tutorials that explain how this is done for the straight-forward cases but there's one area of testing that has proven difficult on most platforms, and that is testing of the user interface. That said, there are a few things that make this an easier problem to solve with Cocoa and in this post I'll explain why.
Another major improvement of OCMock: it now supports more flexible constraints on the expected arguments. This is done in the Objective-C way and user-defined constraints don't have to implement a formal interface, they're just methods in the test class. As usual this release also includes several contributions from the community. More details on the OCMock page at Mulle Kybernetik.
Of the many projects I have worked on the rewrite of the Guardian website is certainly a highlight. And in this case I can even speak about it in detail. In fact, Mat Wall from the Guardian and I presented some of our experiences at several conferences, and now the Software Engineering Radio has published a podcast in which we talk about this project.
It has been in the making for some time but now the ThoughtWorks Anthology is available from the Pragmatic Programmers. The Anthology is a collection of essays written by individual authors from ThoughtWorks covering a wide range of topics that we encounter on our projects. My essay finally gets our thinking on Domain Annotations into writing, after we had presented the ideas at a couple of conferences. A more in-depth description of the Anthology can be found on the Pragmatic Bookshelf.
Working with CruiseControl I've always found CCTray a really useful tool... for Windows. Being a Mac user I decided we really need something like this for the Mac and started working on CCMenu this summer. After a few beta releases this has reached version 1.0 yesterday. Check it out here.
I have looked at applications of visualisations techniques to improve software quality for good while now, and at a QCon conference earlier this year Floyd Marinescu and I chatted about my current thinking. If you are interested, the full interview has been published on InfoQ now. More here.
I've just spent an inspiring day at CITCON 2007, an open space conference about continuous integration and testing. Matching the occasion I have released the last (hopefully) beta version of CCMenu, my Mac equivalent of CCTray.
This is a good year for London. First, we saw JAOO come to London, in cooperation with InfoQ, and now we also get a our version of the No Fluff Just Stuff exchange, in cooperation with Skills Matter. I have heard a lot of great things about it and so I am really pleased that I can finally attend. And, before I forget, I will also give my advanced TDD talk. See you there.
The JAOO conference is one of my absolute favourites and this year I have the honour of hosting a track on enterprise application frameworks. As you might know I'm interested in a variety of development platforms and so I'm excited to have talks on Java and .NET frameworks as well as Ruby on Rails in this track. It is also a rare opportunity for me to be able to talk in depth about some of the work I've done: Mat Wall from the Guardian and I will present a case study on the development of the new Guardian.co.uk website.
This is Open Source week... I finally managed to get out a new release of OCMock, which brings a couple of contributions and improvements around handling of unexpected invocations. The new 'nice' mocks simply ignore these, and the framework now rethrows exceptions in verify. Normally, OCMock follows the fail fast (PDF) philosophy, but some frameworks ignore exceptions when they are thrown, and we still want the test to fail. More details on the OCMock page at Mulle Kybernetik.











 This year, the Java programming language is 20 years old. To mark the occasion, Michael Stal, editor of JavaSPEKTRUM, decided to publish a few anecdotes that we, the members of the content advisory board, would contribute. When I thought about what to write the hype around this year's WWDC was building up, reminding me of the following story.
This year, the Java programming language is 20 years old. To mark the occasion, Michael Stal, editor of JavaSPEKTRUM, decided to publish a few anecdotes that we, the members of the content advisory board, would contribute. When I thought about what to write the hype around this year's WWDC was building up, reminding me of the following story.  Last month three completely unrelated, yet equally mysterious, hardware problems kept me entertained at home. Each did have an obvious explanation in the end. Getting from symptoms to diagnosis, though, required both, guesswork and luck. Sure, I'm more of a software guy but I thought that I had a decent understanding of “how stuff works”. Well, looks like things have gotten pretty complex now.
Last month three completely unrelated, yet equally mysterious, hardware problems kept me entertained at home. Each did have an obvious explanation in the end. Getting from symptoms to diagnosis, though, required both, guesswork and luck. Sure, I'm more of a software guy but I thought that I had a decent understanding of “how stuff works”. Well, looks like things have gotten pretty complex now. 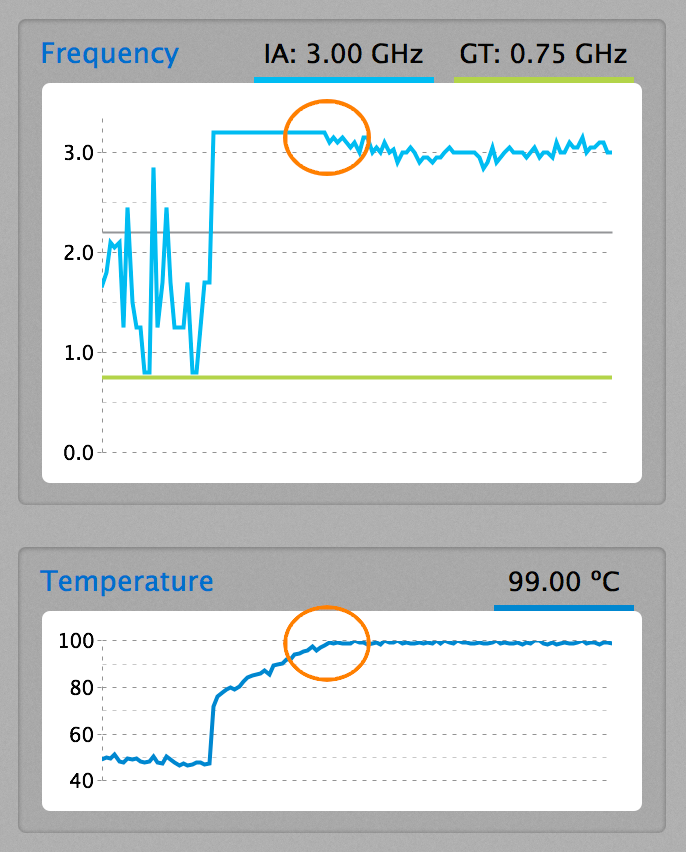

")



 Admittedly, I've been struggling with the "Architect" title in the IT world. It is not that I think there's no role for architecture, far from it, but too often I've encountered architects who focus too narrowly on architecture, losing track of the realities of actual software development and the context in which the software will be used. I wonder, if there was no "Architect" title and people who are responsible for architecture would be called guide or coach or tech lead, or just the senior developer, whether things would be better.
Admittedly, I've been struggling with the "Architect" title in the IT world. It is not that I think there's no role for architecture, far from it, but too often I've encountered architects who focus too narrowly on architecture, losing track of the realities of actual software development and the context in which the software will be used. I wonder, if there was no "Architect" title and people who are responsible for architecture would be called guide or coach or tech lead, or just the senior developer, whether things would be better.  The
The